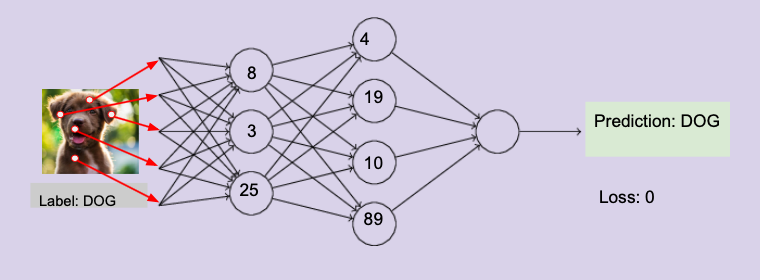
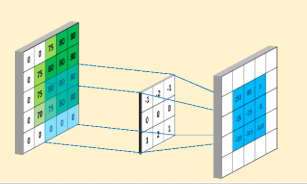
What is Machine Learning?
Artifical Intelligence (AI): A program that can sense, reason, and adapt.
Machine Learning:
- A type of AI where performance improves as they are exposed to more data.
- It uses a lot of data to find patterns.
Deep Learning:
- Type of machine learning where machines can basically do tasks that would usually require human intelligence.
- In deep learning, the machines learn by experience and gain skills without requiring any human involvement.
- The artificial neural networks, algorithms inspired by the human brain, learn from large amounts of data. It would perform tasks repeatedly, each time editing it a bit to improve the outcome so that it can be more accurate.
Difference Between Machine Learning and Deep Learning:
- In machine learning, you have to tell the algorithm what the defining features are.
- In deep learning, you can just give the neural network the data and it will figure out the defining features.